


PRIMER 7与PERMANOVA+:多元数据分析与统计检验完整解决方案
PRIMER 7结合PERMANOVA+软件,为多元数据分析(特别是群落生态学中的物种-样本数据)提供了丰富的图形化和分析流程。该软件几乎适用于所有多元数据集的分析,其核心特性在于能够将数据简化为合适的样本间相似性三角矩阵,进而通过聚类排序技术直观展示样本关联关系,并采用稳健的置换检验进行假设验证。
该工具主要面向生态数据(包括基础研究、环境调查及生物监测中的物种丰度数据,如计数、生物量、覆盖度或存在/缺失数据),虽然主要针对生物群落数据设计,但同样适用于其他类型的多元数据,例如遗传核苷酸(如SNPs)、等位基因频率、氨基酸或蛋白质数据。PRIMER还能处理理化变量数据,既可单独分析这些参数,也能探究生物变化与理化条件之间的协同变异。
更重要的是,通过PERMANOVA+模块,研究人员能够基于多因子抽样设计、复杂实验和/或环境梯度来分析多元(或单变量)变异。该工具直接在选定的相似性度量空间中构建数据分布云,保持了基础分析的灵活性。通过精准构建相关检验统计量与先进的置换算法,实现了无需分布假设的统计推断。
功能特点
数据与结果便捷管理
- 在统一的交互式Windows图形界面中,可同步处理多组数据集、图形及输出文件
- 通过树状导航窗格轻松追踪所有工作进度
- 支持Excel、.csv、.txt或三列格式的数据输入/输出
- 自由调整图形配色、字体及视觉结果
- 支持将结果复制/打印/导出为.jpg、.emf、.tif、.gif、.png、.bmp或.rtf格式
- 关键样本或变量识别
- 按指定条件合并或拆分数据集
- 为检验与展示定义分组结构
- 支持大规模数据集处理(仅受内存限制)
- 内置矩阵展示、热图与核心分析的智能向导
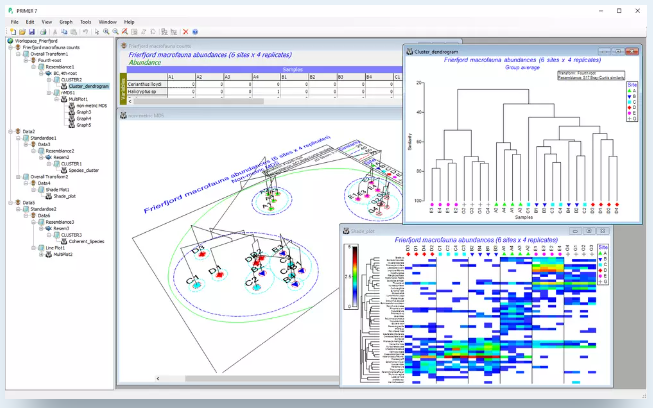
排序分析方法
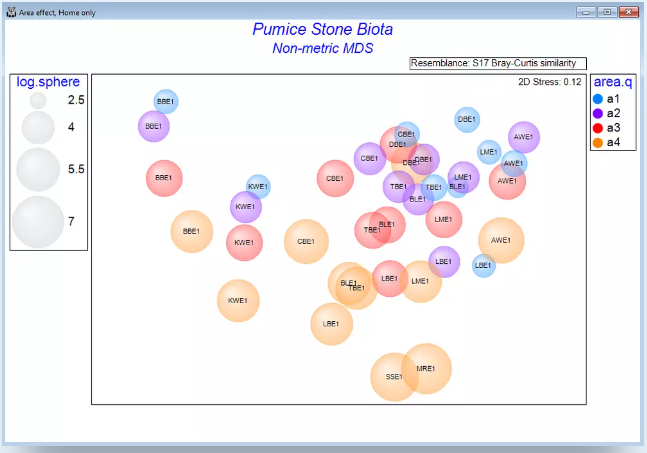
- 实现高维数据的二维/三维可视化
- 提供多种非约束排序技术:主成分分析(PCA)、主坐标分析(PCO)、非度量多维标度(nMDS)、度量多维标度(mMDS)及阈值度量标度(tmMDS)
- 自定义文本、色彩与符号样式
- 通过叠加聚类、轨迹线、气泡图、图像、向量或minimum生成树增强信息呈现
- 采用基于距离的冗余分析(dbRDA)、主坐标典型分析(CAP)等约束排序方法验证假设,或通过联合MDS整合不同变量集
- 通过自助法在MDS图中显示平均数据的置信区间
- 支持排序图的旋转、缩放、动画、保存与共享
聚类分析
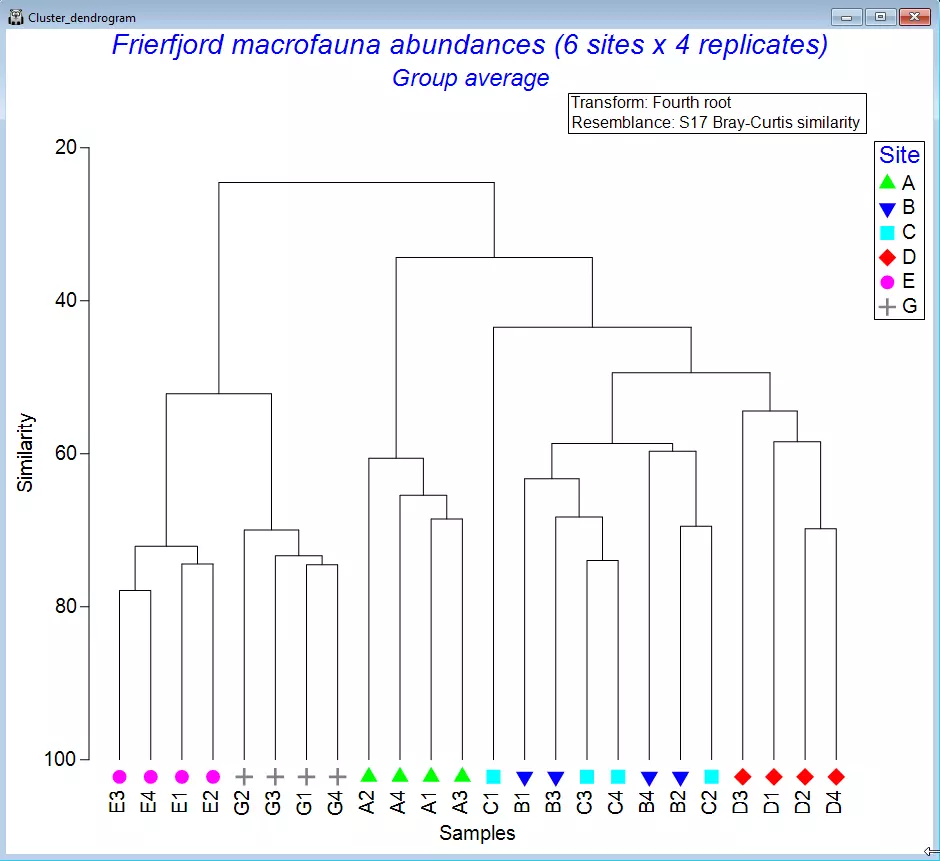
- 执行样本(或变量/物种)的层次聚合聚类
- 提供单一连接、全连接、组平均连接及灵活β连接选项
- 绘制树状图并生成同质距离矩阵
- 通过自定义、旋转、折叠、缩放或打印结果呈现细节
- 运用相似性剖面(SIMPROF)及关联置换检验识别样本/物种的连贯组别
- 分裂聚类法支持非约束(UNCTREE)或环境变量约束(LINKTREE)模式
- 实现指定群组数的非参数K均值聚类(krCLUSTER),或通过SIMPROF自动截断准则确定蕞佳群组数
非参数置换检验
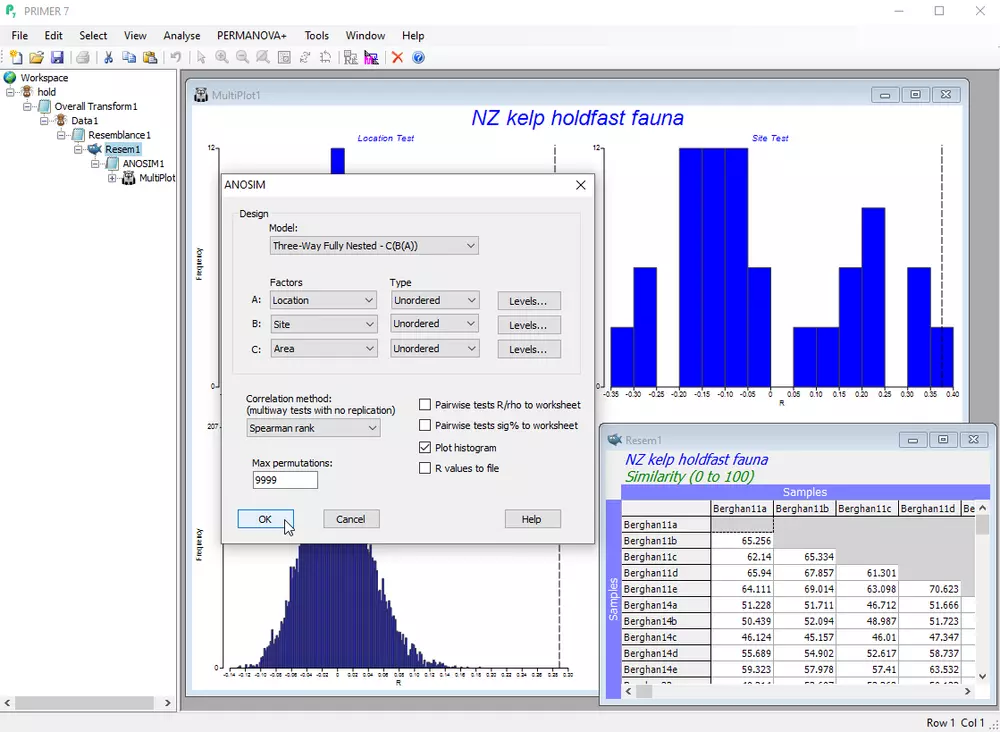
- 采用相似性分析(ANOSIM)检验不同时间、地点、实验处理等多变量样本组的差异
- 支持三因素(可指定有序/无序)的三向设计(含嵌套层次)非参数检验
- 通过非参数Mantel检验(RELATE)分析两个相似性矩阵的关联
- 构建模型矩阵检验群落结构在时空上的序列/周期性变化(如季节节律)
- 通过二阶关联检验(2STAGE)构建并验证多相似性矩阵的整体模式一致性
半参数置换检验
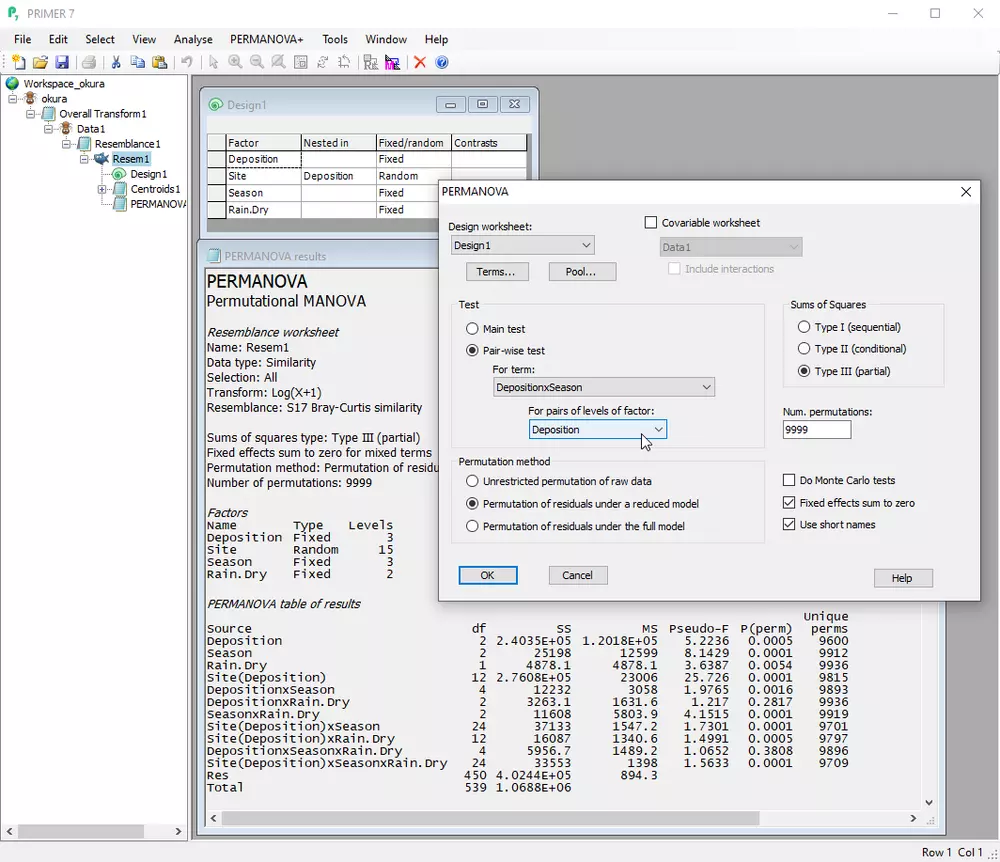
- 基于半参数置换多元方差分析(PERMANOVA),应对含交互项的多因子实验/抽样设计
- 根据选定相似性测度直接划分多元数据,使用欧氏距离可获得经典划分结果
- 支持多因子设计、交互作用、固定/随机效应、嵌套/交叉设计、非对称设计及定量协变量
- 自动识别设计隐含项,支持项目合并或删除
- 基于均方期望(EMS)构建精准反映实验设计的检验统计量
- 采用适应多层级设计的进阶置换技术获取p值,确保稳健无分布的可靠结果
- 提供成对比较与用户指定对比
- 估计效应量/方差组分
- 通过质心距离揭示因子结构中的显著模式
- 支持不平衡或未重复设计(裂区、随机区组等),可选择平方和类型
物种群系与环境关联分析
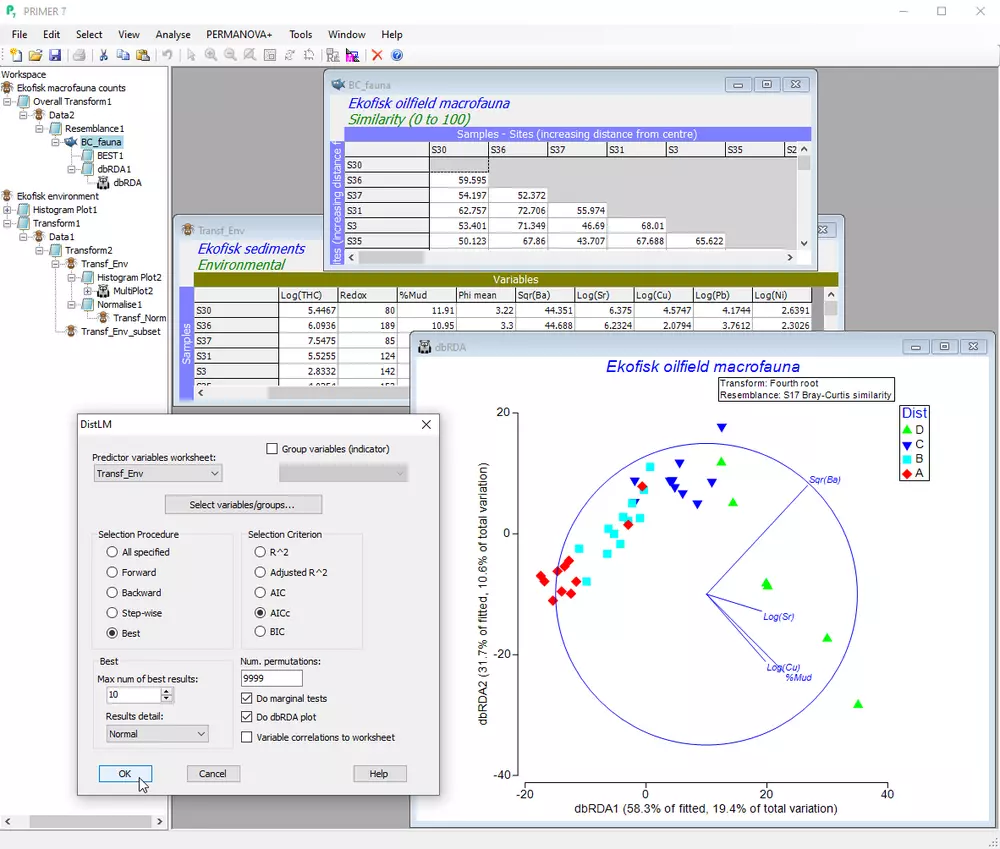
- 建立矩阵间关联(如生物与环境),或通过"BEST"Mantel型匹配识别与环境矩阵匹配的变量子集
- 运用LINKAGE树在环境/空间约束下寻找生物响应数据的分割
- 基于距离的多元多元回归(DISTLM)量化解释变量对环境生物数据变异的影响程度
- 提供单个回归变量的边际与序列置换检验
- 支持前向、后向、逐步及"best"变量选择方法
- 提供模型比较的多元信息准则(AIC、AICc、BIC、校正R方)
- 通过距离基冗余分析(dbRDA)可视化组变量/单个变量的拟合值
- 基于距离的典型相关分析(CAP)探索两组变量间的相互作用
组别/梯度/预测模型表征
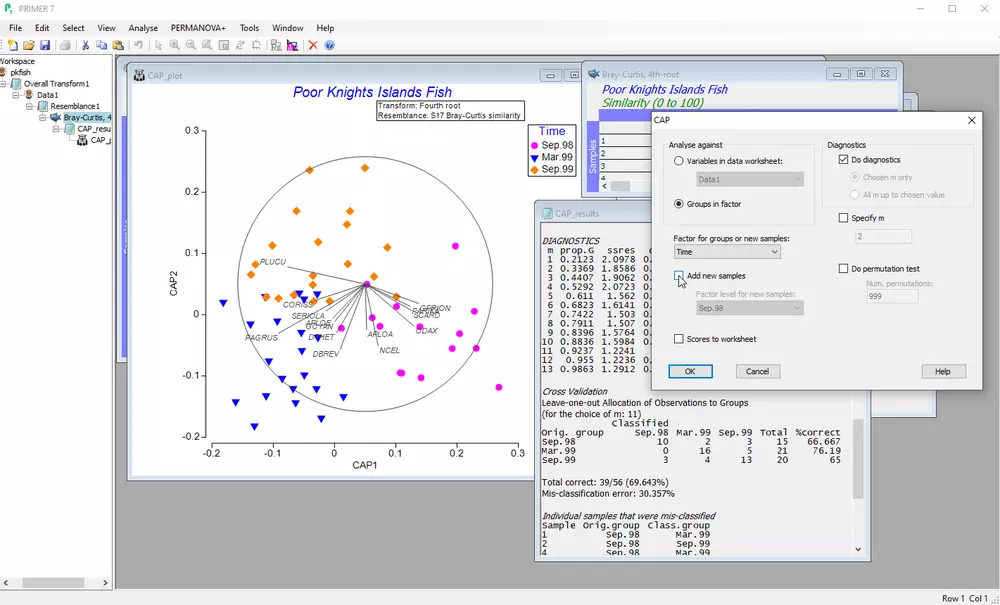
- 通过主坐标典型分析(CAP)在选定相似性测度空间进行判别分析
- 运用SIMPER解析组间/组内差异的贡献物种
- 通过相似性剖面(SIMPROF)及置换检验识别样本/物种的连贯组别
- 使用阴影图/热图高亮关键物种,可叠加聚类或维持指定样本/物种排序
- 留一法交叉验证提供先验组别区分度的统计度量
- 支持新样本归类到现有组别,或沿连续梯度预测新样本位置
- 适用于环境监测计划、形态特征分析或聚类结果的新数据验证
多样性分析
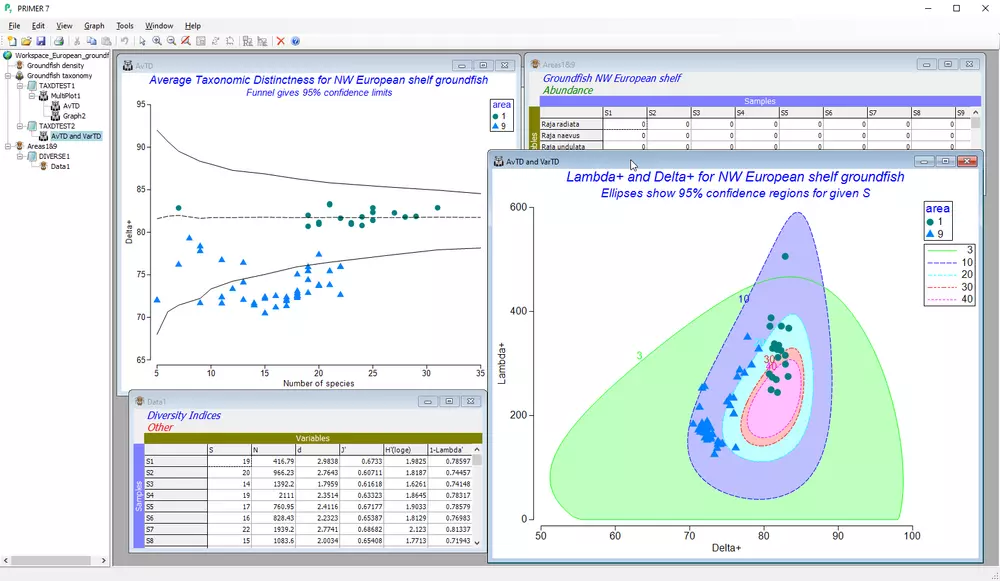
- 整合分类学、功能与系统发育信息进行生物多样性评估,通过二次抽样算法对照主列表检验
- 基于任意相似性测度检验组内多元离散度的同质性(PERMDISP),适用于生态/遗传β多样性研究
- 计算多种经典与新型多样性指数或变量摘要统计量,提供高阶分类层级的数据聚合工具
- 配备灵活的单变量绘图功能:折线图、直方图、散点图、条形图、箱线图、均值图、曲面图或矩阵散点图
- 专设生态学分析工具:优势度曲线、几何级数图、丰度生物量曲线(ABC)等

-
2026-03-26
Origin 2026 SR1 服务更新包发布
Origin 2026 服务更新包1现已发布,适用于更新现有Origin或OriginPro 2026 SR0安装或全新安装。本次更新修正了智能填充、Excel公式、分组绘图批量操作及合并图形兼容性等多处问题,并解决了部分崩溃错误。安装后版本号将升级到10.3.0.197,用户可通过“帮助:关于Origin”确认更新完成。
查看详情 >
-
2026-04-13
GMS 10.9 中文版正式发布 — 新增 PFAS 运移模拟与地下水能量(GWE)模块
GMS 10.9 中文版现已发布。本次更新新增 MODFLOW-USG Transport 对 PFAS 运移模拟的支持、MODFLOW 6 地下水能量(GWE)模型、UGrid 多项改进以及 MODFLOW 6 界面优化等功能,为地下水数值模拟与地热储能分析提供更多工具支持。
查看详情 >
-
2026-03-10
GTAP数据库 V12已正式发布 - 附视频介绍
GTAP(Global Trade Analysis Project)是一个设立在美国普渡大学农业经济系的经济研究组织。该项目成立于1992年,旨在为贸易政策分析和可计算一般均衡(CGE)建模提供数据支持。全新版GTAP V12已于2026年2月正式发布,欢迎联系北京睿驰科技订购正版GTAP数据库。
查看详情 >

