



Stata - 数据统计分析软件包
Stata 是一套提供其使用者数据分析、数据管理以及绘制图表的及整合性统计软件。它提供功能,线性混合模型、均衡重复反复及多项式普罗比模式。集合了数据分析、数据管理以及绘制图表等多种功能于一体的数据统计分析软件,主要用于管理、分析和绘制定量数据,能够执行统计分析。除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归,负二项回归及广义负二项回归,随机效应模型等。该程序适用于处理时间序列、面板和横截面数据。是满足您数据科学需求的解决方案,获取并操纵数据探索可视化模型。
Stata 18版本已推出,为数据分析带来更多全新特性。新版本提供了Bayesian model averaging、Causal mediation analysis、group sequential designs等多项功能,让数据分析更加精准。
对于常见的数据分析,Stata 18新版本提供了更便捷的使用方式,可以根据需要自定义统计表格,并且可以加入统计分组、比较测试等功能。此外,新版本的图形显示也进行了升级,使用更鲜艳的颜色搭配更简洁的背景,使图表更加清晰易读。
Stata 18的新功能
贝叶斯模型平均
不确定在回归中使用哪些预测变量?
使用贝叶斯模型平均来解释分析中的这种不确定性。探索有影响力的模型和预测变量,获得更好的预测等等。

因果调解分析
因果分析量化因果效应。因果调解分析解开了它们。
这些影响是通过另一个变量来调节的吗?估计直接和间接影响。计算调解的比例。

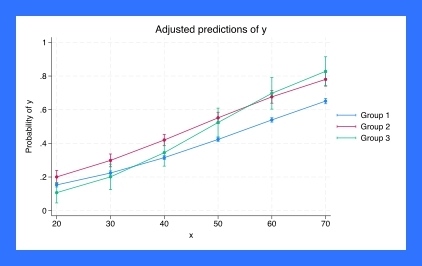
Heterogeneous DID
估计随群体和时间而变化的诊治成果。为重复的横截面或面板数据拟合模型。
可视化成果。群体、时间或暴露于诊治中的总效应。

全新的图形样式
白色背景·水平y轴标签·明亮的调色板·侧面图例·等等
您还可以按变量绘制颜色图。
表格1
使用新的dtable指令更轻松地创建描述性统计表!
导出为Word、Excel、PDF、LaTeX、HTML、Markdown等格式。

跨帧的别名变量
使用来自多个数据集的变量,就像它们存在于一个数据集中一样。
您现在可以使用框架集。

分组顺序设计
计算临床试验的成果和无效停止界限。在测试比例、均值或幸存者函数时,找到中期和结果分析所需的样本量。

多层次meta分析
您的研究是否具有嵌套在多个分组级别中的效应大小?使用多级元分析来解释组合结果时成果大小之间可能存在的依赖性。

患病率的meta分析
你问,我们交付!对比例或流行率进行荟萃分析。生产林地。探索异质性。进行亚组分析。和更多。

线性模型的稳健推理
Stata对线性模型的强大功能变得更加强大。

Wild cluster bootstrap
集群数量少?每个集群的不平等观察?没问题!Wild cluster bootstrap处理所有这些。

RERI
暴露如何相互作用以增加风险?
使用reri找出答案。

具有区间删失Cox模型的TVC
在区间删失Cox分析中加入时变协变量,包括残存和其他函数的预测和绘图!

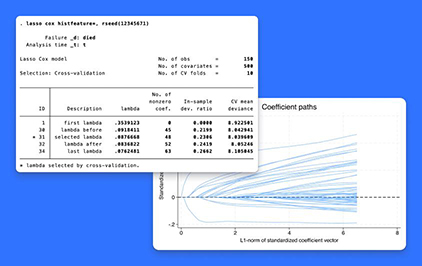
Cox模型的Lasso
使用Lasso和弹性网在Cox模型中选择变量。
计算预测。图形残存者、失败者和其他函数。
生存模型的GOF图
想知道您的生存模型是否适合您的数据?estat gofplot让这变得简单。将其与右删失和区间删失数据、参数和半参数模型等一起使用。

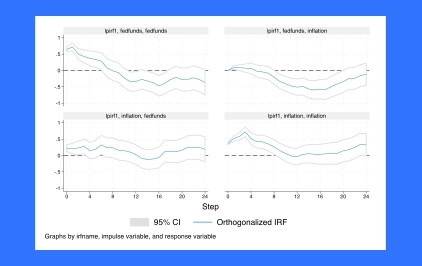
IRF的本地预测
通过局部投影估计脉冲响应函数 (IRF)。检验多个IRF系数的假设。图IRF、正交化IRF和动态乘数。
ARIMA和ARFIMA模型选择
使用AIC、BIC和HQIC比较潜在的ARIMA或ARFIMA模型。选择理想数量的自回归和移动平均项。

灵活的需求系统
估计一篮子商品的需求。评估对价格和支出变化的敏锐性。从八个需求系统中进行选择,包括Cobb–Douglas、translog、AIDS 和QUAIDS。

IV分位数回归
估计协变量对结果条件分布分位数的影响。考虑内生性。跨分位数绘制系数。

IV分数概率模型
建模比例或比率?
有内生协变量吗?
使用ivfprobit拟合您的模型。

界面增强
数据编辑器——可固定的行和列、截断文本的工具提示、标题中的变量标签等等。
Do-file Editor — 自动备份和突出显示用户定义的关键字的语法。
哪个Stata适合您
不管您是学生还是有经验的研究人士,我们都会提供合适您需求的软件包:
-
Stata / MP:速度快的Stata版本(用于四核,双核和多核/多处理器计算机),可以分析大的数据集
-
Stata / SE:标准版,对于更大的数据集
-
Stata / BE:基础版,用于中型数据集
-
Stata的数值:用于嵌入式和Web应用程序的Stata
Stata / MP是运行速度快的Stata版本。任意当前的计算机都可以利用Stata / MP的多处理功能。其中包括Intel i3 , i5 , i7, i9 , Xeon , Celeron和AMD多核芯片。在双核芯片上,Stata / MP在耗时的估算命令上的总体运行速度提高了40%,在相关位置运行速度提高了72%。Stata /MP如果具有两个以上的内核或处理器,速度会更快。
Stata / MP,Stata / SE和Stata / BE均可在任意计算机上运行,但Stata / MP的运行速度更快。
Stata/MP还可以分析比其他版本的Stata更多的数据。如果使用目前大的计算机,Stata/MP可以分析10到200亿个观测值,并且一旦计算机硬件赶上,就可以分析多达1万亿个观测值。
Stata/SE和Stata/BE的区别在于各自可以分析的数据集大小。与Stata/SE(至多798个)相比,Stata/SE(至多10,998个)和Stata/MP(至多65,532个)可以拟合包含更多具有自变量的模型。Stata/SE可以分析多达20亿个观测值。
Stata/BE允许具有多达2,048个变量和20亿个观测值的数据集。Stata/BE在一个模型中至多可以有798个独立变量。
Stata的数值可以在嵌入式环境中支持上面列出的数据大小。
兼容的操作系统
平台
适用于Windows®的STata
-
Windows 11*
-
Windows 10*
-
Windows Server 2022,2019, 2016, 2012R2*
STata需要使用64位Windows来处理Intel®和AMD制造的X86 - 64处理器
适用于Mac®的Stata
配备Apple Silicon或Intel处理器的Mac
macOS 11.0 (Big Sur) 或更高版本的 Macs with Apple Silicon 和 macOS 10.13 (High Sierra) 或更高版本的 Macs with Intel 处理器
用于Linux的STata
运行Linux的64 位(Core i3等效或更好)
要求包括GNU C library (glibc) 2.17或更高版本和libcurl4
对于xstata,您需要安装GTK 2.24
硬件要求
| 配置 | 内存 | 磁盘空间 |
|---|---|---|
| Stata/MP | 4GB | 2GB |
| Stata/SE | 2GB | 2GB |
| Stata/BE | 1GB | 2GB |
Stata for Linux需要可以显示数千种颜色或更多颜色的显卡(16位或24位颜色)


- 2026-07-21
- 2026-07-15
- 2026-07-15
- 2026-07-03
- 2026-06-30
- 2026-06-25

- 2026-07-21
- 2026-07-16
- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15










