



GAUSS - 矩阵语言数据分析软件
GAUSS一个为数学和统计而设计的互动环境,是一个分析环境,具有评估,预测,模拟,可视化等所需的内置工具。30年多年来一直被主要机构的数据依赖领域的人员所采用。
基于高效的GAUSS矩阵编程语言,易于使用的数据分析,数学和统计环境。

互动和快捷
GAUSS平台为探索数据,执行计算和分析结果提供了一个交互的环境。这些交互式功能可加快您的工作流程,而其快捷的GAUSS分析引擎可加快您的计算速度。
GAUSS分析引擎的设计很轻巧,高效,同时充分利用了您的硬件。从小型笔记本到大型集群。
可视化和演示
直观的交互式和编程方法,可以方便创建美观的2D和3D图形,分析您的数据并展示您的发现。您的高分辨率GAUSS图形可以导出很多的格式,例如:PNG,PDF,SVG,TIFF等。
用于建模和分析的综合环境
GAUSS是一套复杂的分析环境,适合执行计算,数百万数据点的复杂分析或介于两者之间的任意计算。不管您是刚接触使用计算机进行分析的新手或是一位有经验的程序员,GAUSS产品系列组合提供给您方便的学习环境,功能足够处理您想解决的数值任务,自从1984年以来,GAUSS已经成为数值计算和大型数据的复杂建模标准。
GAUSS系统能够被描述成:高效的数值处理器,编程语言和一套交互式的分析环境。
交互快捷
对于小型问题,GAUSS提供了交互式的环境,用于探索数据,创建情境和分析结果。对于复杂任务,您能够自己编写程序并把他们保存到硬盘。GAUSS计算结果很快,提供堪比用C或FORTRAN编译的程序性能。
直接和高效
尽管很多GAUSS用户从来没有发现需要大量编程的需要,对于那些需要这么做的用户,GAUSS提供了快速学习和功能强的自然和逻辑环境。GAUSS的核心是高效的足够执行复杂分析的编程语言。在GAUSS中分析的基本单元是矩阵,使得语法很类似通常的数学表达式。既然矩阵运算被设定,那么原因需要的大部分循环语句被删除了。数据转换循环允许通过直接在表达式中使用变量名称在数据集中转换变量。这种流畅的数据转换使得程序更短,更方便阅读。GAUSS资源调试器大大的简化了程序开发。有着您想要在调试系统中能得到的,您在运行时识别和解决逻辑错误的问题。
语言
作为一个复杂的编程语言,GAUSS系统是强的,GAUSS用户可以立即使用大量统计,数学和矩阵处理程序。GAUSS能够被用于交互式的简短的一次性命令或通过创建好几个文件和函数库,或在可视化和介绍之间的任意东西的程序。
另外,GAUSS自动而且便捷处理复杂数值。您不需要跟踪真实和虚伪的矩阵部分。复杂数值被自动处理大大简化了工程或需要处理复杂数值任务的编程。
对于现代分析来说,没有能像GAUSS那样提供:
-
按照您的思维方式进行编码
您可以用笔和纸尽快地直接从GAUSS的新期刊中对想法和技术进行编码。GAUSS矩阵语言是将数学,统计和机器学习代入生活中的自然方法。

-
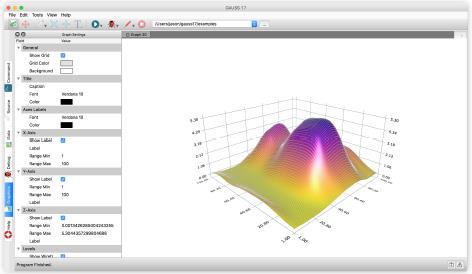
打造视觉效果
以交互方式或编程方式定制引人入胜的数据故事。
-
智能编译器+高效代码+并行化=更快的分析
GAUSS是经过三十多年高效本机代码的产物。结合我们的编译器和现代线程功能,您可以在竞争之前获得答案。
现成解决方案库
GAUSS应用模块为众多类型的分析,提供预构建的解决方案,包括贝叶斯估计,约束,金融,时间序列等。提供了源代码,允许无限定制。

集成到几乎任意环境中
有效地将分析功能连接到内部或面向客户的数据源,应用程序与GAUSS Engine的接口。

行业解决方案
对于从金融到物理的数据驱动型学科的人员,GAUSS长期以来一直是专属模型,技术和应用程序的来源。但是,GAUSS还是一个环境,可为您提供开发,调整,执行和生成几乎任意问题或项目的出版物质量图形所需的。
GAUSS是快速原型制作以及广泛实施学科和商业模型的理想选择。用户可以更改功能和程序,并便捷与C/C++,Java,FORTRAN和其他环境集成。
GAUSS应用程序是一套内部与编程和可修改程序,可帮助用户解决其计算需求。
GAUSS 23版本的功能
数据触手可及
-
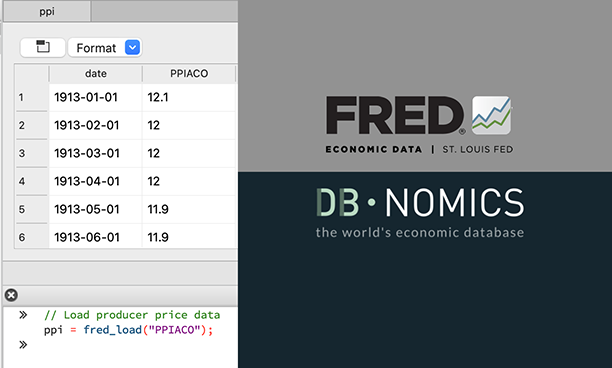
通过FRED和DBnomics集成访问数百万个经济和金融数据系列
-
在导入期间聚合、过滤、排序和转换FRED数据系列
-
从GAUSS搜索FRED系列
从Internet上的任意位置加载数据
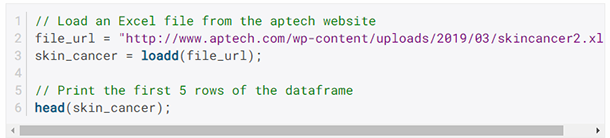

使用...简化数据加载
自动类型检测
以前的版本需要带有关键字的公式字符串来指定某些文件类型中的日期,字符串和分类变量。

GAUSS 23中的智能数据类型检测会找出变量类型,因此您无需手动指定。自动检测近40种日期格式。

自动标题和分隔符检测
像这样替换旧代码:

和

自动处理
-
存在或不存在标题行
-
分隔符(制表符、逗号、分号或空格)
-
行数和列数
-
变量类型
数据帧存储
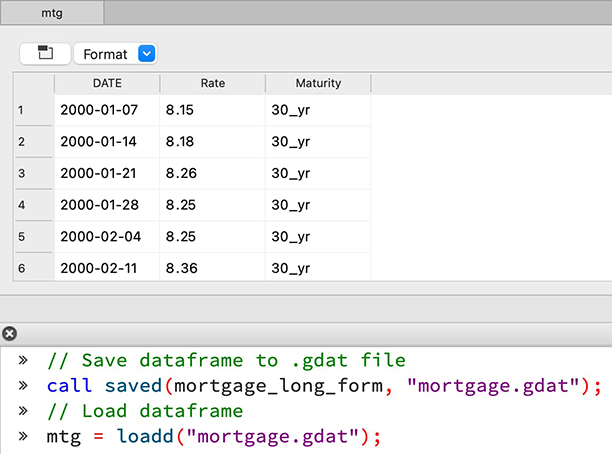
无需学习新代码,只需使用带有.gdat文件拓展名来加载和存储数据帧。
扩展分位数回归
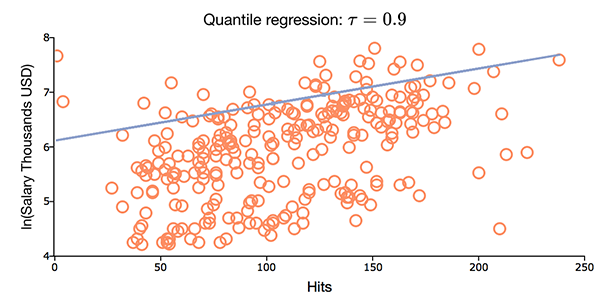

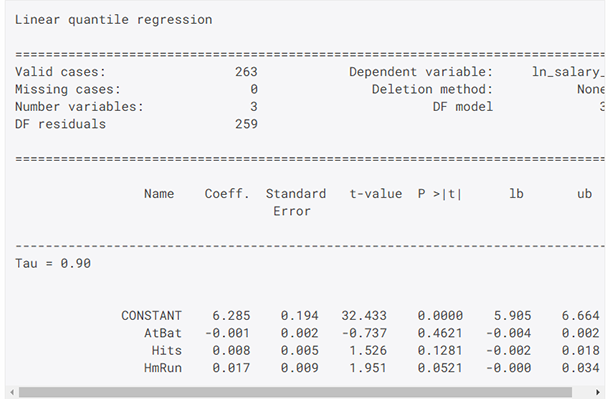
-
新的核估计方差-协方差矩阵
-
高达4倍的速度提升
-
扩展模型诊断,包括pseudo R平方、系数t统计和p值以及自由度
核密度估计
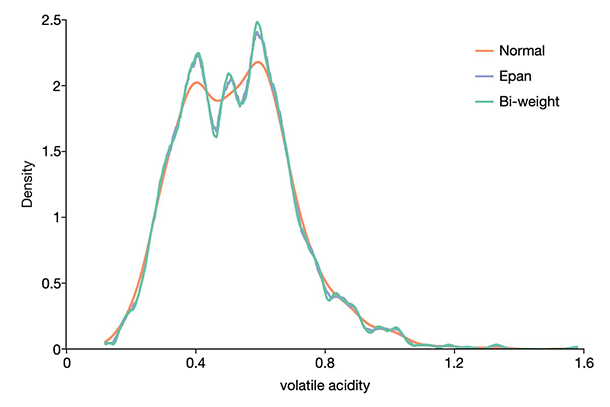
-
使用13个可用内核估计未知概率函数
-
自动或用户指定的带宽
-
具有易于使用的自定义选项的核密度图
改进的协方差计算

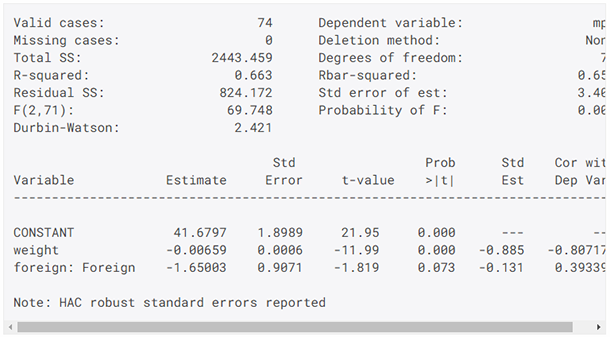
-
用于计算Newey-West HAC robust标准误差的新程序
-
全部稳健的协方差程序现在都包括关闭小样本校正的选项
-
扩展数据框和公式字符串兼容性
数据清洗和探索的新功能
between
返回一个二进制向量,指示哪些观测值落在指定范围内。它可以与selif选择行一起使用。支持日期和有序分类列。

where
提供一种方便直观的方式来组合或修改数据。它根据条件从a或b返回元素。


-
使用skewness和kurtosis函数探索样本对称性和尾部
-
使用新的JarqueBera函数测试正态性
加速和效率改进
-
使用shiftc和lagn创建滞后时,速度可提高10倍,内存使用量可减少50%。
-
高达2倍的加速(或更大的数据)和50%的内存使用量减少,以防丢失。
-
对于逐个元素数学(+, -, .*, ./)、关系(.>, .<, .>=, .<=, .==, .!=)和逻辑(.and, .not, .or, .xor)运算符,速度可提高2倍(或更高,对于大数据),内存使用率可降低50%。
-
在某些情况下,使用indsav的速度可提高100倍
-
高达40%的重新分类速度
-
使用loadd和数据导入窗口加载Excel文件的速度提高了3倍


- 2026-07-15
- 2026-07-15
- 2026-07-03
- 2026-06-30
- 2026-06-25
- 2026-06-25

- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15











