



Comprehensive Meta-Analysis (CMA) - 元分析软件
Comprehensive Meta-Analysis (CMA)是一款元分析(也称综合分析、整合分析)软件,可对多个研究数据进行统计整合,再次分析。如这些研究结论保持,Meta-Analysis可验证这些研究的共同效应。如果研究结论有差异,Meta-Analysis则用于验证产生差异的原因。
CMA 版本4有什么新内容:
报告
只需单击一下,程序就会创建一个文档,以适合发布的格式报告全部统计数据。
第二次单击该程序将对该文档进行注释并解释全部统计数据的含义以及假设和限制。
第三次单击该程序将该文档导出到Word。

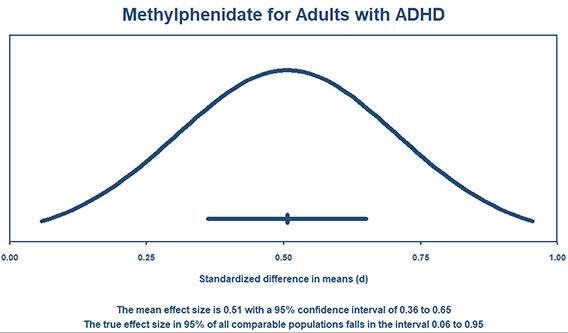
预测区间
在任意元分析中,关键的是要报告平均效应量以及效应量在不同研究中的差异范围。这种分散由预测间隔解决。这使我们能够报告,例如,平均效应量时0.50的标准化平均差,但在任意单个人群中,真实效应量可能低至0.05或高达0.95。很多报告元分析的指南现在都要求包含预测区间。
在版本4中,该程序提供了将预测区间显示为forest图的一部分的选项。此外,只需单击一下,您就可以创建一个图表,显示真实效果的整个分布。再单击一次,您可以将其导出到Word或PowerPoint。
CMA软件功能介绍
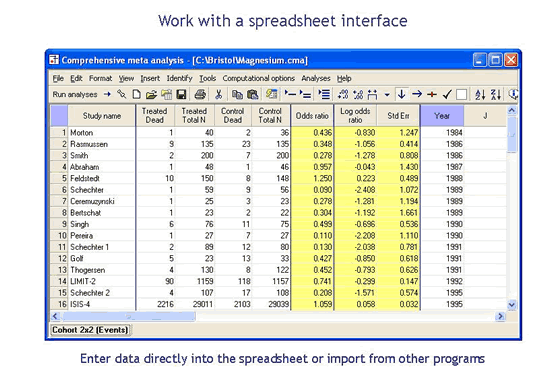
使用电子表格界面
直接输入数据或从其他程序导入数据
您可以直接将数据键入电子表格,就像使用任意基于电子表格的程序一样。或者,如果您当前正在使用其他程序进行元分析,您可以直接从该程序复制数据或使用向导导入数据。
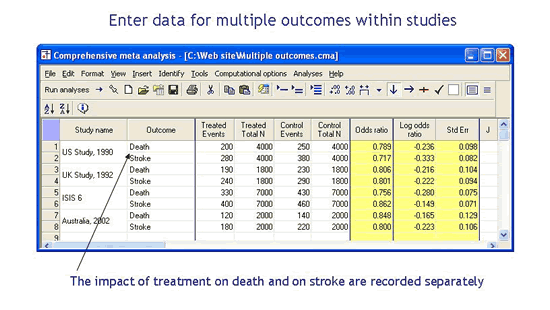
如果我在研究中有多个亚组或结果怎么办?
该程序允许您处理报告多个子组、结果、时间点或比较的数据的研究。该程序使得为这些研究输入数据变得方便,并提供了很多选项以在分析中使用它们。
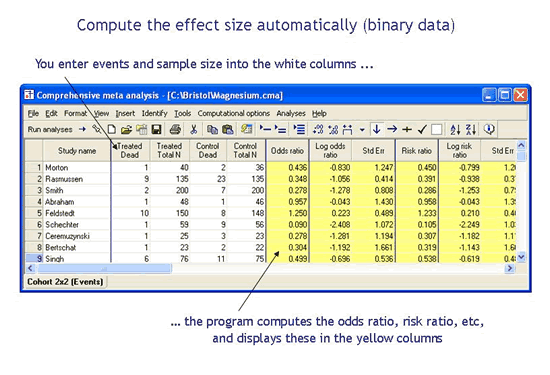
自动计算效果大小
在每一项元分析中,您从每项研究的已发表的摘要数据开始,并计算治疗效果(或效果大小)。例如,如果一项研究报告了组中事件的数量,您可能想要计算优势比。或者,如果一项研究报告均值和标准差,你可能想要计算标准化的均值差异。这种计算效果大小的过程通常是乏味且耗时的。在某些情况下,尤其是当研究以不同格式呈现数据时,该过程也很困难且轻易出错。
使用CMA,过程快速且准确
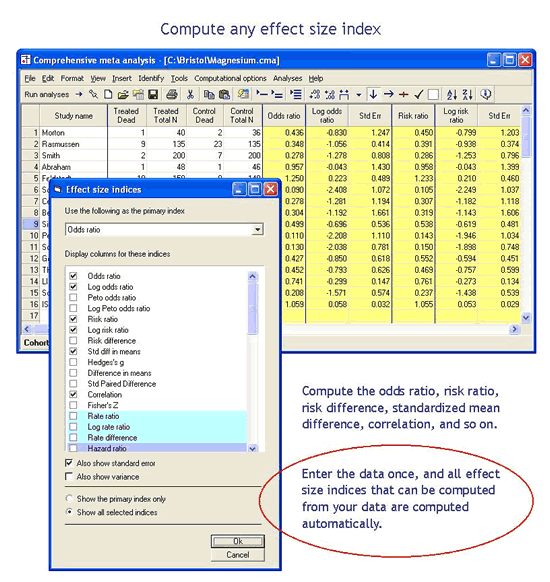
使用CMA,您可以输入已发表研究中报告的任意摘要,程序会根据该摘要数据计算效果大小。例如,您可以输入事件和样本大小,程序会计算优势比。或者,您可以输入均值和标准差,程序将计算标准化均值差。此处显示了三个示例(选自一百多个选项)。
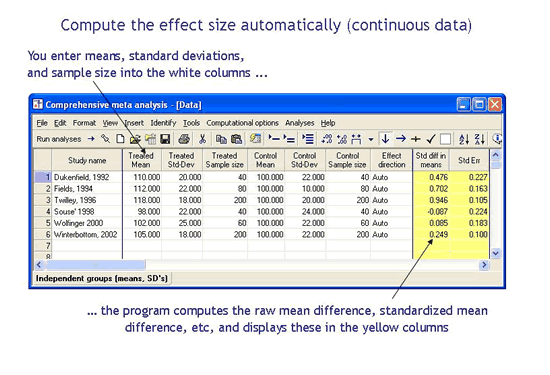
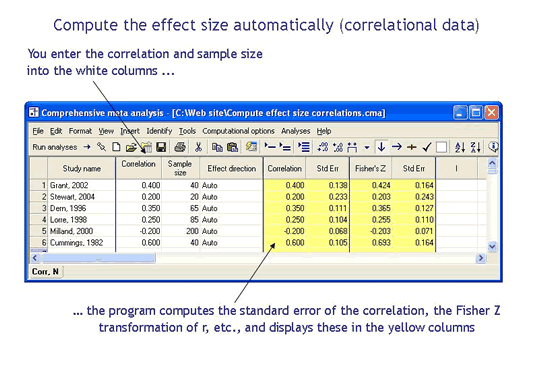
如果我的数据是其他格式怎么办?
如果您的研究以其他格式报告数据怎么办?也许您的研究只报告了p值和样本量。或者,您的研究报告了优势比和置信限。对于任意其他程序,在进行分析之前,您需要计算每项研究的效应大小和方差。相比之下,CMA允许您输入几乎全部类型的数据—它包括100种数据输入格式,类似于上面显示的三种。只需在列表中找到您的数据类型,CMA就会在电子表格中创建相应的列。
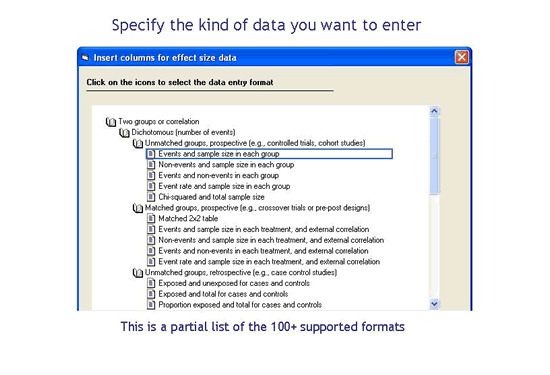
程序使用什么公式来计算这些影响?
要查看用于计算效果大小的公式,请双击该效果大小。该程序会打开一个对话框,显示所使用的确切公式以及该特定行的全部计算细节。
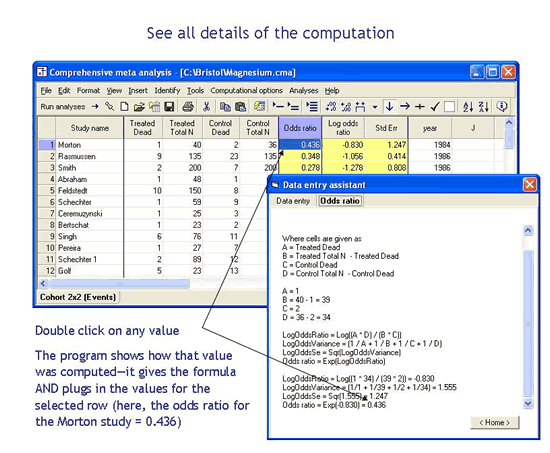
如果我想使用另一个治疗效果指标怎么办?
在上面显示的示例之一中,我们输入了事件和样本量,程序计算了优势比和风险比。如果您更愿意使用风险比率怎么办?或者,如果您想计算与比值比相对应的标准化均值差怎么办?在另一个示例中,我们输入均值和标准差,程序计算标准化均值差。如果您更愿意使用原始均值差,或者计算与标准化均值差对应的相关性怎么办?
CMA允许您使用您选择的指数,并在指数之间来回切换。
例如,如果您输入了事件和样本量,程序将计算优势比、对数优势比、风险比、对数风险比、风险差、标准化均值差 (d)、偏差校正标准化均值差 (g )、相关性和Fisher的z。或者,如果您输入均值和标准差,程序将计算原始均值差、标准化均值差 (d)、偏差校正标准化均值差 (g)、相关性、Fisher's z、对数优势比和优势比。
这些示例是支持的格式和索引的子集。
如果不同的研究报告不同类型的数据怎么办?
上面,我们展示了您可以自定义数据输入屏幕以接受几乎全部类型的数据。但是有哪些不同的研究提供了不同类型的数据呢?例如,如果一项研究报告事件和样本量而另一项研究报告优势比和置信区间怎么办?您如何将这两种数据输入程序?
CMA允许您混合和匹配不同的数据格式。您可以为前几项研究输入事件和样本量,然后为接下来的几项研究输入优势比和置信区间,为其他研究输入优势比和方差,等等。或者,您可以为某些研究输入均值和标准差,为其他研究输入p值,为其他研究输入t值,等等。您可以根据需要使用多种数据格式自定义电子表格。该程序将计算它们每个的影响大小,并(在可能的范围内)允许您将它们全部包含在统一分析中。

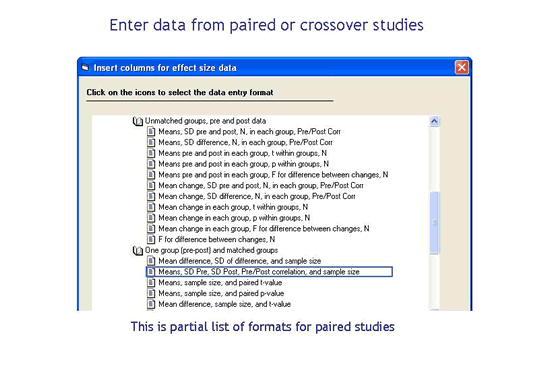
如果我的部分(或全部)研究包括事前事后或交叉设计怎么办?
CMA包括20多种前后或交叉设计的模板,这一点很关键,因为否则可能难以计算这些模板的标准误差。而且,您可以将这些研究与只使用后测的研究混合搭配。
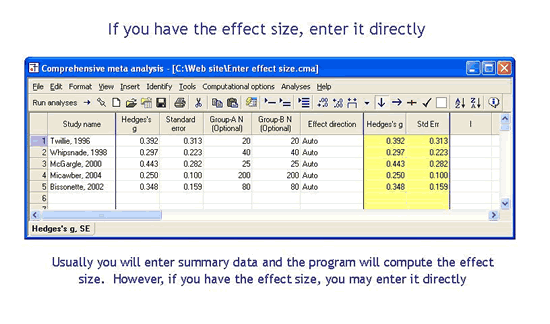
如果我已经计算了效果大小怎么办?
如果您已经计算了效应大小及其方差(或标准误差),您可以直接输入这些(与以任意其他格式输入数据相同)。
我可以混合二进制、连续和相关数据吗?
如上所述,该程序允许您以多种格式输入汇总数据——例如,一项研究的事件和样本量以及另一项研究的优势比和置信区间。但在这个例子中,两项研究都使用了二进制数据。如果一些研究报告二进制数据(事件和样本量)而其他研究报告连续数据(均值和标准差)或相关数据怎么办?
该程序能够跨这些不同类别的数据进行转换。它将在比值比、标准化平均差和相关性之间进行转换,以便全部这些都可以用于同一分析。
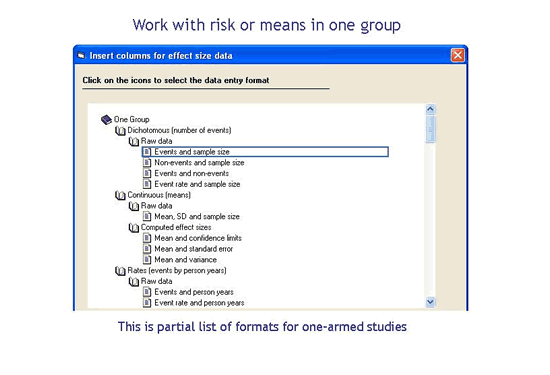
如果我的研究着眼于点估计而不是效应量或治疗效果怎么办?
虽然大多数元分析使用效应量(评估两个变量之间的关系),但有些元分析用于估计一组中的风险、比率或均值(例如,“Lyme disease的风险是多少?”)。CMA 也将处理这些影响(或点估计)。
我可以对回归权重进行元分析吗?
是的。除了能够处理公认的效果(例如比值比和平均差)之外,该程序还能够处理通用点估计,这些估计可以在原始尺度或对数尺度上进行分析。
快速准确的进行元分析
单击一次即可进行核心元分析并创建一个显示,作为后续全部内容的路线图。
此显示是一个交互式森林图,可以清楚的了解数据—分析中包含多少研究、每项研究的准确度、研究之间的效果是否一致或研究之间有很大差异,等等。然后您可以根据需要自定义此显示。添加或删除列、设置计算选项、打开包含附加统计信息的表。下面是一些例子。
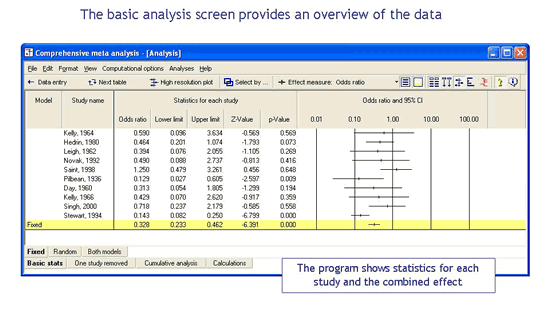
显示研究权重
只需单击一下,您就可以包含一个列,显示分配给每个研究的相对权重。有了这种机制,就可以清楚地知道综合效应是很多研究的函数,还是主要有一小部分研究驱动。
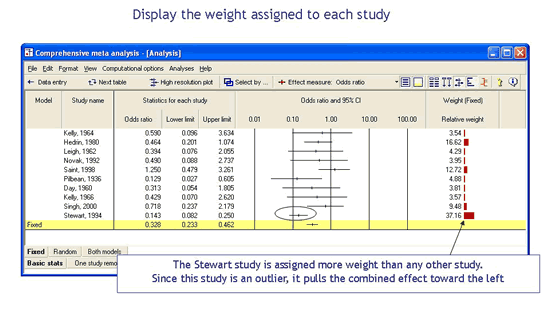
选择计算模型
单击选项卡以选择固定效应模型或随机效应模型。您还可以同时显示两者,这样可以查看两个模型之间的点估计和置信区间有何不同。
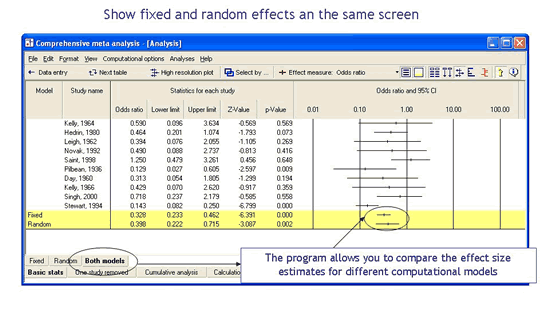
了解计算模型如何影响研究权重
该程序还将并排显示固定效应分析和随机效应分析的相对权重。这有助于解释为什么当我们从固定效应模型转向随机效应模型时,综合效应会发生变化。
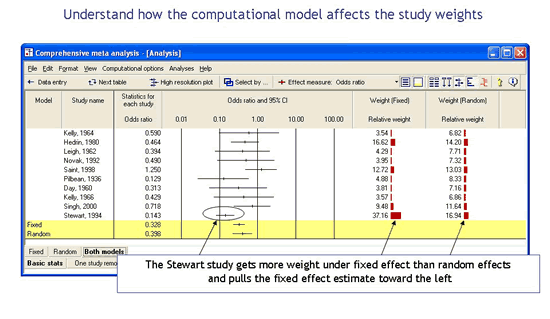
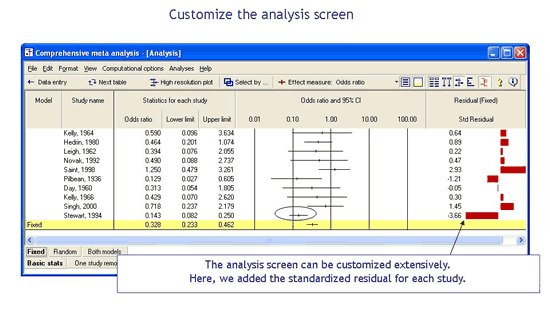
自定义分析屏幕
您可以控制为每项研究显示的统计数据。您可以显示基本统计数据,例如效果大小、标准误差和置信限度。您可以显示计数,例如每个组的事件和样本大小。您可以显示每个研究的诊断,例如残差(从研究到组合效应的距离)。
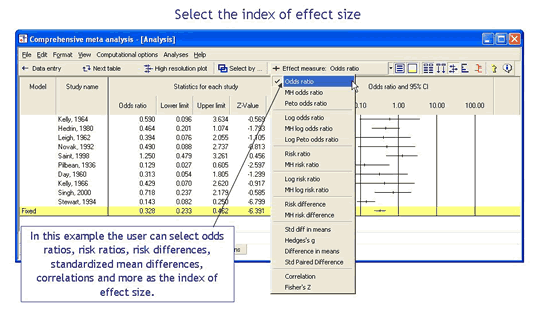
选择效应量指标
工具栏包括一个下拉框,其中列出了处理效果(或效果大小)的全部可用指标。当您选择优势比或标准化平均差等效应大小时,全部统计数据、权重和图表都会自动更新。
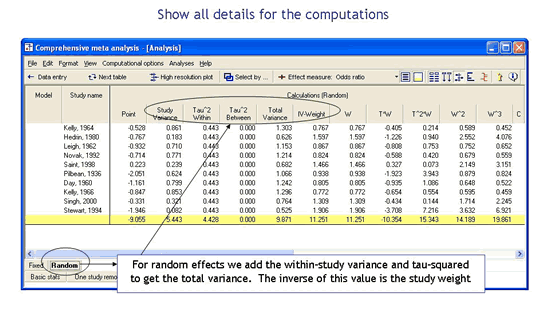
显示计算的全部细节
全部计算都显示在电子表格上。您可以查看此电子表格并实际遵循计算的全部细节。如果您使用自己的电子表格进行元分析,您可以将此电子表格与您自己的进行比较。这也是一种特有的教学工具。
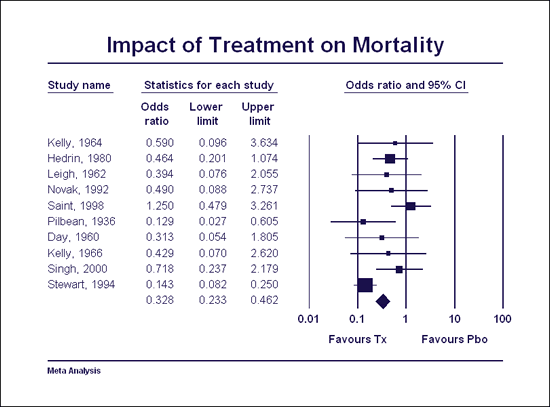
单击一下即可创建高分辨率森林图
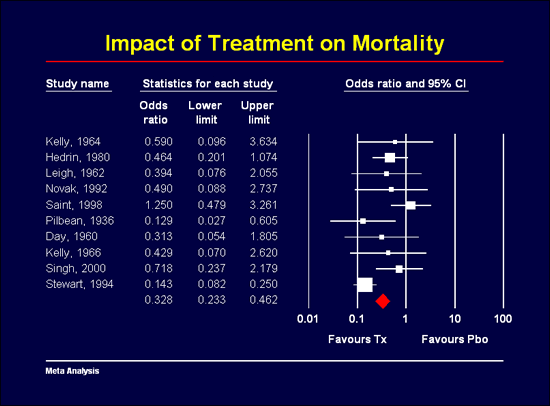
任意元分析的一个关键要素是森林图—该图显示每项研究的影响大小的精度以及综合效果。该图为分析提供了一个面貌—它显示了综合效应是基于少数研究还是基于很多研究,效应大小是一致的还是变化的,等等。因此,森林图在帮助研究人员理解数据以及将研究结果传达给其他人方面发挥着核心作用。
大多数其他元分析程序使用为其他目的开发的图形引擎,并将它们用于创建森林图。相比之下,CMA中的绘图引擎是专为元分析目的而开发的。它很易于使用,并提供了广泛的关键选项。
一键创建高分辨率绘图,然后自定义绘图上的任意元素。为研究、子组和整体效果选择符号。或者,指定符号的大小应与研究权重成正比,这样对综合效果贡献大的研究很轻易被发现。为图表上的每个元素设置颜色和字体,然后单击一下即可导出到Word或PowerPoint!
将绘图导出到PowerPoint
只需单击一下,您就可以打开PowerPoint并插入当前幻灯片的副本。整个过程大约需要2秒。
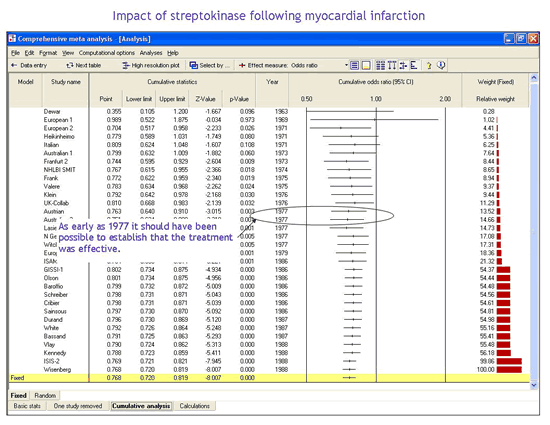
使用累积元分析来查看证据如何随时间发生变化
累积元分析实际上是一系列元分析,其中序列中的每个分析都包含一个额外的研究。例如,分析中的开始一行可能包含1990年发表的研究,下一行可能包含1990年和1991年发表的研究,依此类推。累积元分析可以回顾性地进行,以显示证据主体如何随时间发生变化,或前瞻性地进行,在完成时将新研究添加到证据主体中。
虽然累积元分析常用于随时间追踪证据,但它也可用于显示证据如何随其他因素变化。例如,我们可以按研究规模对数据进行排序并运行累积分析。在这种情况下,该程序将显示只包含largest研究的综合效应(朝向顶部),以及这种效应如何随着较小的研究被添加到分析中而发生变化。同样,我们可以从更高质量的研究开始,看看随着其他研究的加入,效果如何变化。
使用“删除一个”分析来衡量每项研究的影响
作为敏感性分析的一部分,我们可能想要评估每项研究对综合效应的影响。例如,异常值或很大的研究对综合效果有何影响?或者,一项小型研究是否有影响?
为了解决这些类型的问题,程序将自动对除开始一个研究之外的全部研究运行分析,然后是除第二个研究之外的全部研究,依此类推。生成的图表一目了然地显示了每项研究的影响。
此外,您可以选择在删除任意研究或一组研究的情况下运行分析——这些可以通过名称或调节变量的值来选择。
处理数据的子集
运行分析时,您可以选择(或过滤)任意变量或变量组合。您可以按研究名称包括或排除研究。您可以包括在“Double-blind”中被评为“是”的研究。您可以将年龄编码为“老年”且患者类型编码为“慢性”的研究包括在内。
在研究中处理多个亚组或结果
该程序允许您为研究中的多个亚组、结果、时间点或比较输入数据,并提供各种选项来处理这些分析。
评估调节变量的影响
当不同研究的效应量有很大差异时,元分析的一个关键目标可能是了解这种差异的原因。
使用方差分析来评估分类调节器的影响。例如,“对于急性患者的治疗是否比对慢性患者更有效?” 或“作业比辅导更有效吗?”
使用元回归评估连续调节变量的影响。例如,“治疗效果是否随着剂量的增加而增加?”,或“效果大小是否与学生的年龄有关?”
评估发表偏倚的潜在影响
Meta分析提供了可用数据的数学准确综合,但可能会担心紧要研究比非紧要研究更有可能发表,因此可用数据库可能存在偏差。该程序包括一组可用于评估这种偏差的潜在影响的函数,作为一种敏感性分析。
系统要求
-
Windows 7或更高版本
-
32位或64位
-
屏幕:XGA或更高
-
磁盘空间:25MB
-
MACS:要在Mac上运行程序,需要使用Windows模拟器,例如Parallels或Bootcamp。建议不要使用Wine或CRossOver。


- 2026-07-21
- 2026-07-15
- 2026-07-15
- 2026-07-03
- 2026-06-30
- 2026-06-25

- 2026-07-21
- 2026-07-16
- 2026-07-15
- 2026-07-15
- 2026-07-15
- 2026-07-15









